layout: true <div class="header-logo"><img src="images/logos/cvpr21.jpg" /></div> .center.footer[Spyros GIDARIS and Andrei BURSUC | Advances in Self-Supervised Learning: Introduction] --- class: center, middle, title-slide count: false ## .bold[CVPR 2020 Tutorial] # Leave Those Nets Alone: <br> Advances in Self-Supervised Learning <br> .grid[ .kol-3-12[ .bold[Spyros Gidaris] ] .kol-3-12[ .bold[Andrei Bursuc] ] .kol-3-12[ .bold[Jean-Baptiste Alayrac] ] .kol-3-12[ .bold[Adrià Recasens] ] ] .grid[ .kol-3-12[ .bold[Mathilde Caron] ] .kol-3-12[ .bold[Olivier Hénaff] ] .kol-3-12[ .bold[Aäron van den Oord] ] .kol-3-12[ .bold[Relja Arandjelović] ] ] .foot[https://gidariss.github.io/self-supervised-learning-cvpr2021/] --- class: center, middle, title-slide count: false ## CVPR 2020 Tutorial ## .bold[Leave Those Nets Alone: <br> Advances in Self-Supervised Learning] # Introduction <br> .grid[ .kol-2-12[ ] .kol-4-12[ .bold[Spyros Gidaris] ] .kol-4-12[ .bold[Andrei Bursuc] ] .kol-2-12[ ] ] .reset-columns[ ] .center.width-20[] .foot[https://gidariss.github.io/self-supervised-learning-cvpr2021/] --- class: middle, center # Motivation --- class: middle .center.bigger[Deep Learning + Supervised Learning is a really cool and strong combo.] .center.width-90[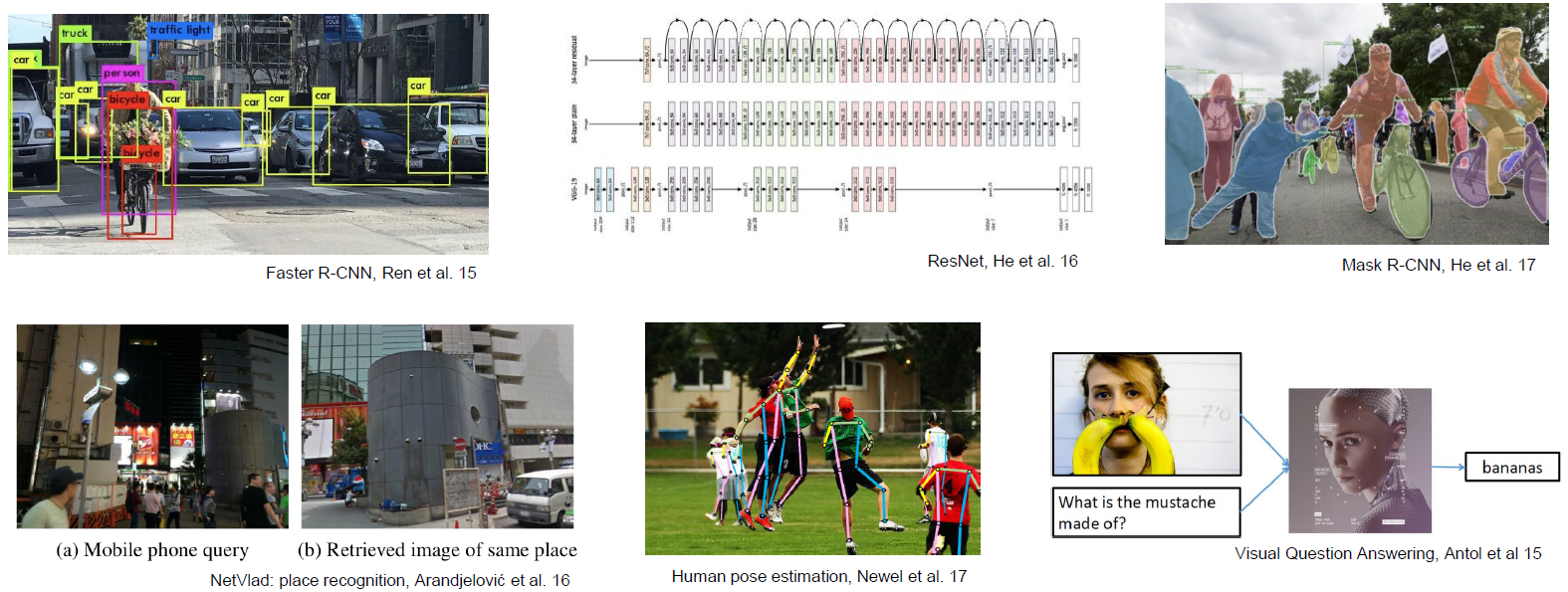] <!--.caption[VGG-16 preditions on original and artificially texturised images.]--> --- class: middle ## .center[Deep Learning: how it works?] .center.width-90[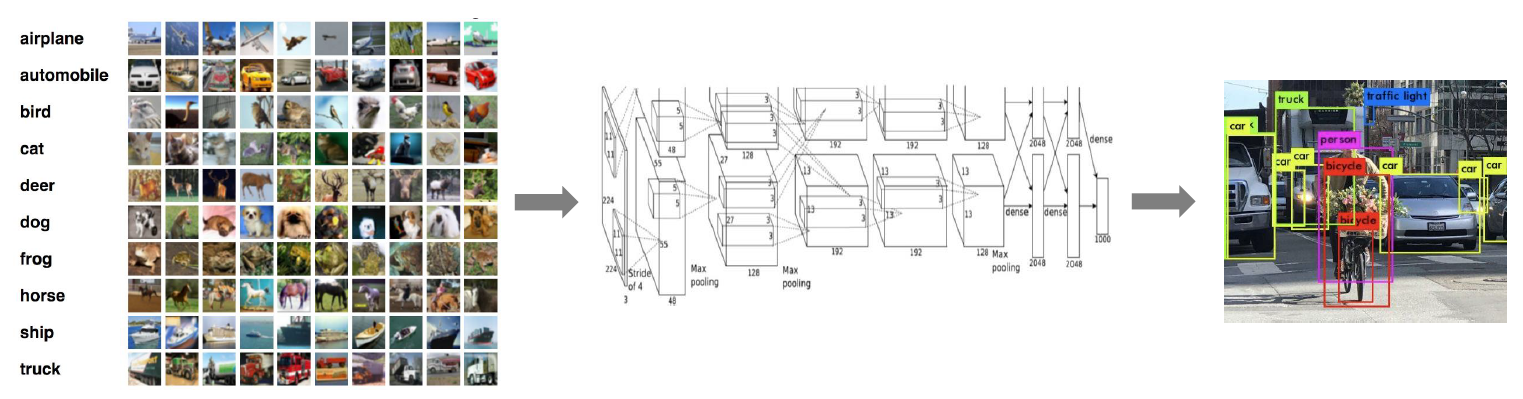] - Predefine the set of visual concepts to be learned - Collect diverse and large number of examples for each of them - Train a deep model for several GPU hours or days --- class: middle, center .big[Meanwhile, in the real world ...] --- class: middle ## Difficult to acquire and curate large human-annotated datasets .center.width-60[] <br> <br> .grid[ .kol-5-12[ - Requires intense human labor - annotating + cleaning raw data - Time consuming and expensive - Error prone (human mistakes) ] .kol-7-12[ .center.width-90[] .caption[Annotating such image: ~1.5h] ] ] --- class: middle ## Difficult to keep the pace with an ever changing world .center.width-80[] .caption[Men's fashion trends 1980-1989] - Data distributions shift all the time, e.g., fashion trends, new Instagram filters - Infeasible to launch large annotation campaigns each time .citation[Credit image: [La Polo](https://www.lapolo.in/blog/100-years-mens-fashion/)] --- class: middle ## Difficult to keep the pace with an ever changing world .center.width-80[] .caption[Super Mario from 1981 to 2017] - Sensors specs are frequently upgraded - Infeasible to launch large annotation campaigns each time --- class: middle, center .big[Can we exploit anything from raw data?] --- class: middle ## Exploiting raw unlabeled data .center.width-90[] <br> <br> - Acquiring raw unlabeled data is usually easy - However, typical supervised methods cannot exploit them --- class: middle, center .bigger[Deep Learning requires *large amounts* of *carefully labeled data* which is **difficult to acquire** and **expensive to annotate**.] --- class: middle, center .bigger[Even with large amounts of data, supervised learning still has several blind-spots in terms of **learning useful and rich representations**. ] --- class: middle ## .center[The supervision signal can bias the network in unexpected ways] .center.width-90[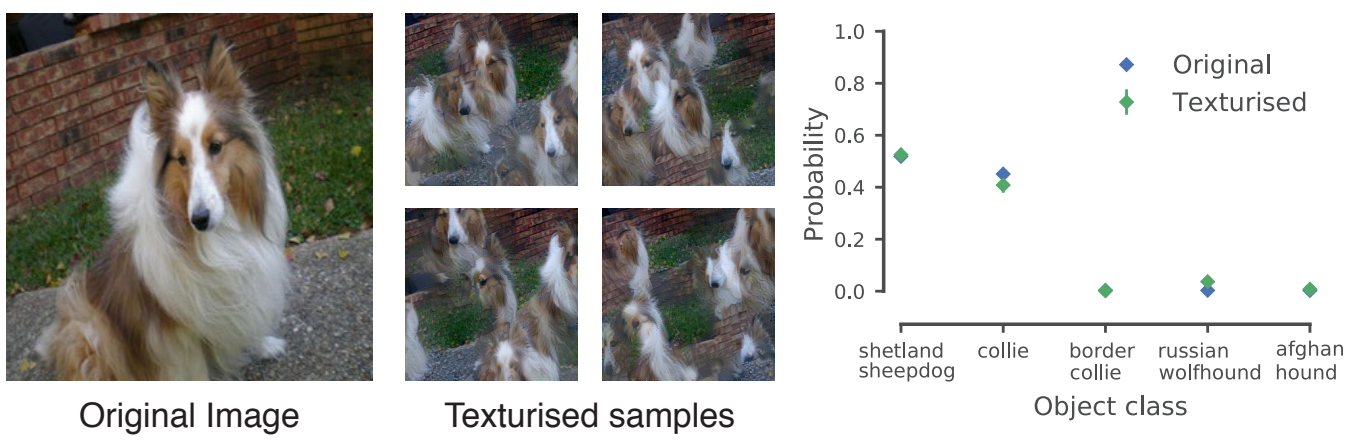] .caption[VGG-16 preditions on original and artificially texturised images.] .citation[L.A. Gatys et al., Texture and art with deep neural networks, Neurobiology 2017] --- class: middle ## .center[The supervision signal can bias the network in unexpected ways] .center.width-85[] .caption[Classification predictions of a ResNet-50 trained on ImageNet] .citation[R. Geirhos et al., ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness, ICLR 2019] --- class: middle ## .center[Self-supervision to the rescue?] .center.width-60[] .caption[Bottom images are transformed such that local statistics are preserved while global statistics are altered.] .hidden[ Train a linear binary classifier original vs. transformed images over $\texttt{conv5}$ features from: + model pre-trained on ImageNet labels $\rightarrow$ accuracy of $78\%$ + model pre-trained with self-supervision $\rightarrow$ accuracy of $85\%$ ] .citation[S. Jenni, Steering Self-Supervised Feature Learning Beyond Local Pixel Statistics, CVPR 2020] --- count: false class: middle ## .center[Self-supervision to the rescue?] .center.width-60[] .caption[Bottom images are transformed such that local statistics are preserved while global statistics are altered.] Train a linear binary classifier original vs. transformed images over $\texttt{conv5}$ features from: + model pre-trained on ImageNet labels $\rightarrow$ accuracy of $78\%$ + model pre-trained with self-supervision $\rightarrow$ accuracy of $85\%$ .citation[S. Jenni, Steering Self-Supervised Feature Learning Beyond Local Pixel Statistics, CVPR 2020] --- class: middle, center .bigger[Improving representation learning requires features that are *not specialized for solving a particular supervised task*, but rather *encapsulate richer statistics for various downstream tasks*.] --- class: middle ## .center[Inspiring success from self-supervision in NLP, e.g., **word2vec** ] .center.width-85[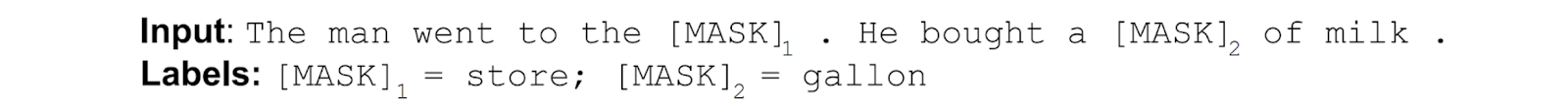] .caption[Missing word prediction task.] .center.width-85[] .caption[Next sentence prediction task.] .citation[T. Mikolov et al., Efficient estimation of word representations in vector space, ArXiv 2013 <br/>T. Mikolov et al., Distributed representations of words and phrases and their compositionality, NeurIPS 2013<br/>J. Devlin, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, ArXiv 2018] --- class: middle # What is self-supervision? <br/> - .bigger[A form of unsupervised learning where the **data (not the human) provides the supervision signal**] .hidden[ - .bigger[Usually, *define a pretext task* for which the network is forced to learn what we really care about] ] .hidden[ - .bigger[For most pretext tasks, *a part of the data is withheld* and the network has to predict it] ] .hidden[ - .bigger[The features/representations learned on the pretext task are subsequently used for a different *downstream task*, usually where some annotations are available.] ] --- count: false class: middle # What is self-supervision? <br/> - .bigger[A form of unsupervised learning where the **data (not the human) provides the supervision signal**] - .bigger[Usually, *define a pretext task* for which the network is forced to learn what we really care about] .hidden[ - .bigger[For most pretext tasks, *a part of the data is withheld* and the network has to predict it] ] .hidden[ - .bigger[The features/representations learned on the pretext task are subsequently used for a different *downstream task*, usually where some annotations are available.] ] --- count: false class: middle # What is self-supervision? <br/> - .bigger[A form of unsupervised learning where the **data (not the human) provides the supervision signal**] - .bigger[Usually, *define a pretext task* for which the network is forced to learn what we really care about] - .bigger[For most pretext tasks, *a part of the data is withheld* and the network has to predict it] .hidden[ - .bigger[The features/representations learned on the pretext task are subsequently used for a different *downstream task*, usually where some annotations are available.] ] --- count: false class: middle # What is self-supervision? <br/> - .bigger[A form of unsupervised learning where the **data (not the human) provides the supervision signal**] - .bigger[Usually, *define a pretext task* for which the network is forced to learn what we really care about] - .bigger[For most pretext tasks, *a part of the data is withheld* and the network has to predict it] - .bigger[The features/representations learned on the pretext task are subsequently used for a different *downstream task*, usually where some annotations are available.] --- class: middle ## .center[Example: Rotation prediction] .center.width-70[] .center[Predict the orientation of the image] .citation[S. Gidaris et al., Unsupervised Representation Learning by Predicting Image Rotations, ICLR 2018] --- # Self-supervised learning pipeline .center.bold.bigger[*Stage 1:* Train network on pretext task (without human labels)] .center.width-90[] --- count:false # Self-supervised learning pipeline .center.bold.bigger[*Stage 1:* Train network on pretext task (without human labels) ] .center.width-90[] .center.bold.bigger[*Stage 2:* Train classifier on learned features for new task with fewer labels] .center.width-90[] --- count:false # Self-supervised learning pipeline .center.bold.bigger[*Stage 1:* Train network on pretext task (without human labels)] .center.width-90[] .center.bold.bigger[*Stage 2:* Fine-tune network for new task with fewer labels] .center.width-90[] --- class: middle, black-slide ## .center[Karate Kid and Self-Supervised Learning] .center.width-85[] .caption[The Karate Kid (1984)] --- class: middle, black-slide ## .center[Stage 1: Train .italic[muscle memory] on pretext tasks] .grid[ .kol-4-12[ .center.width-100[] ] .kol-4-12[ .center.width-100[] ] .kol-4-12[ .center.width-100[] ] ] .hidden[ .grid[ .kol-6-12[ $$\begin{aligned} \text{Mr. Miyagi} &= \text{Deep Learning Practitioner} \\\\ \text{Daniel LaRusso} &= \text{ConvNet}\end{aligned}$$ ] .kol-6-12[ $$\begin{aligned}\text{daily chores} &= \text{pretext tasks} \\\\ \text{learning karate} &= \text{downstream task}\end{aligned}$$ ] ] ] --- class: middle, black-slide ## .center[Stage 1: Train .italic[muscle memory] on pretext tasks] .grid[ .kol-4-12[ .center.width-100[] ] .kol-4-12[ .center.width-100[] ] .kol-4-12[ .center.width-100[] ] ] .grid[ .kol-6-12[ $$\begin{aligned} \text{Mr. Miyagi} &= \text{Deep Learning Practitioner} \\\\ \text{Daniel LaRusso} &= \text{ConvNet}\end{aligned}$$ ] .kol-6-12[ $$\begin{aligned}\text{daily chores} &= \text{pretext tasks} \\\\ \text{learning karate} &= \text{downstream task}\end{aligned}$$ ] ] --- class: middle, black-slide ## .center[Stage 2: Fine-tune skills rapidly] .center.width-60[] --- class: middle, center .Q[.big[Is this actually useful in practice?]] --- class: middle ## .center[Transfer learning - object detection] .grid[ .kol-7-12[ .center.width-100[] .caption[Object detection with Faster R-CNN fine-tuned on VOC $\texttt{trainval07+12}$ and evaluated on $\texttt{test07}$. Networks are pre-trained with self-supervision on ImageNet.] ] .kol-5-12[ <br> - Rapid progress in self-supervised learning - Self-supervised methods are starting to outperform supervised methods - This is a __key milestone for self-supervised methods__ as they are finally showing their effectiveness to complex downstream tasks. ] ] --- <br/> Loosely speaking, multiple old and new approaches could fit, at least partially, the definition of self-supervised learning: - input or feature reconstruction: .cites[[Hinton and Salakhutdinov (2006); Vincent et al. (2008); Gidaris et al. (2020), Grill et al. (2020)]] - generating data: .cites[[Goodfellow et al., (2014)]] - training with paired signals: .cites[[V. De Sa (1994); Arandjelovic and Zisserman (2017)]] - hiding data from the networks: .cites[[Doersch et al. (2015); Zhang et al. (2017)]] - instance discrimination: .cites[[Dosovitskiy et al. (2014); van der Ooord et al. (2018)]] ... .citation[G. Hinton and R. Salakhutdinov, Reducing the Dimensionality of Data with Neural Networks, Science 2006 <br/> P.Vincent et al.,Extracting and Composing Robust Features with Denoising Autoencoders, ICML 2008 <br/> S. Gidaris et al., Learning Representations by Predicting Bags of Visual Words, CVPR 2020 <br/> J.B. Grill et al., Bootstrap your own latent: A new approach to self-supervised Learning, NeurIPS 2020 <br/> I. Goofellow et al., Generative Adversarial Networks, NeurIPS 2014 <br/> V. De Sa, Learning classification from unlabelled data, NeurIPS 1994 <br/> R. Arandjelovic and A. Zisserman, Look, Listen and Learn, ICCV 2017 <br/> R. Zhang et al., Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction, CVPR 2017 <br/> C. Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015 <br/> A. Dosovitskiy et al., Discriminative Unsupervised Feature Learning with Convolutional Neural Networks, NeurIPS 2015 <br/>A. van der Oord et al., Representation Learning with Contrastive Predictive Coding, ArXiv 2018 ] --- class: middle # .center[Scope] <!-- .center.big[In this tutorial, we **focus** on self-supervised methods that lead to *useful representations* (good baselines by themselves or amenable to improved performances after fine-tuning on a downstream task) *obtained through* the invention of *a pretext task and/or hiding a part of the original data* to the network.] --> .center.bigger[In this tutorial, we **focus** on self-supervised methods that lead <br/> to *useful representations*, obtained through the invention of *a pretext task* and/or *by hiding a part or view of the original data* to the network.] --- class: middle, center # Evaluating Self-Supervised methods --- class: middle .bigger[Self-supervised methods are evaluated on a range of datasests and tasks .cites[[Goyal et al. (2019); Zhai et al. (2019)]]] .bigger[In most benchmarks the model is *pre-trained on ImageNet* on a pretext task and *subsequentely fine-tuned on other datasets* or protocols.] .citation[P. Goyal et al., Scaling and Benchmarking Self-Supervised Visual Representation Learning, ICCV 2019 <br/> X. Zhai et al., A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark, ArXiv 2019] --- class: middle # Evaluation tasks <br/> ## Linear classification / probe <br/> ## Efficient learning <br/> ## Transfer learning --- # Linear classification / probe .center.width-70[] - Simplest evaluation of the utility of learned representations: fit a linear classifier (FC layer, linear SVM) - .bold[Typical datasets:] ImageNet, Places205, Pascal VOC07 (image classification), COCO14 (image classification), iNat .citation[P. Goyal et al., Scaling and Benchmarking Self-Supervised Visual Representation Learning, ICCV 2019] --- class: middle .center.width-60[] .caption[ImageNet Top-1 accuracy of linear classifiers trained on representations learned with different self-supervised methods (pretrained on ImageNet).] .citation[T. Chen et al., A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020] --- class: middle .center.width-50[] .caption[ImageNet Top-1 accuracy of linear classifiers trained on representations learned with different self-supervised methods (pretrained on ImageNet).] .citation[J. B. Grill et al., Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning, NeurIPS 2020] --- # Annotation efficient classification .center.width-70[] - Fine-tune pre-trained network on a subset of labels $1\\%{-}100\\%$ - .bold[Datasets:] ImageNet, VTAB ??? - ImageNet is still the most popular choice, though new datasets are proposes now, e.g. VTAB benchmark --- class: middle .grid[ .kol-6-12[ .center.width-100[] .caption[ImageNet accuracy of models trained with few labels: CPCv2 vs. supervised] ] .kol-6-12[ <br><br><br> <br> - Supervised networks do not generalize well from few labeled data - Self-supervised networks reach significantly better accuracy in the low data regime ] ] .citation[O. Henaff et al., Data-Efficient Image Recognition with Contrastive Predictive Coding, ArXiv 2019 ] --- # Transfer learning .center.width-70[] - The pre-trained model is augmented with task specific modules (e.g., decoders for semantic segmentation, RPN for object detection) and fine-tuned partially or completely - .bold[Tasks and datasets:] .smaller-x[ + Object detection: VOC07, VOC12, COCO14 + Semantic segmentation: Cityscapes, ADE20K + Other tasks: Surface Normal Estimation (NYUv2), Visual Navigation (Gibson) ] .citation[ P. Goyal et al., Scaling and Benchmarking Self-Supervised Visual Representation Learning, ICCV 2019 ] --- class: middle ## Leave Those Nets Alone: <br> Advances in Self-Supervised Learning - 10:00 - 10:30 EDT (16:00 - 16:30 CET) Introduction _.italic.smaller-x[by Spyros and Andrei]_ - 10:35 - 11:00 EDT (16:35 - 17:00 CET) Contrastive learning _.italic.smaller-x[by Olivier and Aäron]_ - 11:05 - 12:00 EDT (17:05 - 18:00 CET) Teacher-student approaches _.italic.smaller-x[by Spyros and Andrei]_ - 12:05 - 12:50 EDT (18:05 - 18:50 CET) Clustering-style self-supervised learning _.italic.smaller-x[by Mathilde]_ - 12:55 - 13:50 EDT (18:55 - 19:50 CET) Multi-modal approaches _.italic.smaller-x[by Jean-Baptiste and Adrià]_ - 13:55 - 14:30 EDT (19:55 - 20:30 CET) What is next? --- count: false class: middle ## Leave Those Nets Alone: <br> Advances in Self-Supervised Learning - .gray[10:00 - 10:30 EDT (16:00 - 16:30 CET) Introduction .italic.smaller-x[by Spyros and Andrei]] - 10:35 - 11:00 EDT (16:35 - 17:00 CET) Contrastive learning _.italic.smaller-x[by Olivier and Aäron]_ - 11:05 - 12:00 EDT (17:05 - 18:00 CET) Teacher-student approaches _.italic.smaller-x[by Spyros and Andrei]_ - 12:05 - 12:50 EDT (18:05 - 18:50 CET) Clustering-style self-supervised learning _.italic.smaller-x[by Mathilde]_ - 12:55 - 13:50 EDT (18:55 - 19:50 CET) Multi-modal approaches _.italic.smaller-x[by Jean-Baptiste and Adrià]_ - 13:55 - 14:30 EDT (19:55 - 20:30 CET) What is next? --- layout: false class: end-slide, center count: false The end.