layout: true .center.footer[Marc LELARGE and Andrei BURSUC | Deep Learning Do It Yourself | 14.1 Benefits of depth] --- class: center, middle, title-slide count: false ## Going Deeper # 14.1 Benefits of depth <br/> <br/> .bold[Andrei Bursuc ] <br/> url: https://dataflowr.github.io/website/ .citation[ With slides from A. Karpathy, F. Fleuret, G. Louppe, C. Ollion, O. Grisel, Y. Avrithis ...] --- # Reputation of Deep Learning .grid[ .kol-6-12[ .center.width-95[] ] .kol-6-12[ ] ] --- count: false # Reputation of Deep Learning .grid[ .kol-6-12[ .center.width-95[] ] .kol-6-12[ - .Q[Why would it be a good idea to stack more layers?] - .Q[Are there any theoretical insights for doing his? Empirical ones?] ] ] --- # Outline ## Universal approximation theorem ## Why going deeper? ## Regularization in deep networks ### classic regularization: $L\_2$ regularization ### implicit regularization: Dropout, Batch Normalization ## Residual networks --- count: false # Outline ## Universal approximation theorem ## Why going deeper? ## .gray[Regularization in deep networks] ### .gray[ classic regularization: $L\_2$ regularization] ### .gray[ implicit regularization: Dropout, Batch Normalizatio]n ## .gray[Residual networks] --- class: center, middle # Going deeper --- # Universal function approximation .bold[Theorem.] ( Hornik et al, 1991) Let $\sigma$ be a nonconstant, bounded, and monotonically-increasing continuous function. For any $f \in C([0, 1]^{d})$ and $\varepsilon > 0$, there exists $h \in \mathbb{N}$ real constants $v\_i, b\_i \in \mathbb{R}$ and real vectors $w_i \in \mathbb{R}^d$ such that: $$ | \sum\_i^h v\_i \sigma(w\_i^Tx + b\_i) - f (x) | < \varepsilon $$ that is: neural nets are dense in $C([0, 1]^{d})$. .citation[K. Hornik et al., Approximation Capabilities of Multilayer Feedforward Networks, 1991] .credit[Credits: O. Grisel & C. Ollion, [M2DS Deep Learning](https://m2dsupsdlclass.github.io/lectures-labs/), IP Paris] -- count: false - It guarantees that even a single hidden-layer network can represent any classification problem in which the boundary is smooth; - It holds for several activation functions, including ReLU (Sonota & Murata 2015) - It does not inform about good/bad architectures, nor how they relate to the optimization procedure. --- class: middle .bold[Theorem] (Barron, 1992) The mean integrated square error between the estimated network $\hat{F}$ and the target function $f$ is bounded by $$O\left(\frac{C^2\_f}{q} + \frac{qp}{N}\log N\right)$$ where $N$ is the number of training points, $q$ is the number of neurons, $p$ is the input dimension, and $C\_f$ measures the global smoothness of $f$. .hidden[__.bold[tl;dr:]__ Provided enough data, it guarantees that adding more neurons will result in a better approximation.] .credit[Credits: G. Louppe, [INFO8010 Deep Learning](https://github.com/glouppe/info8010-deep-learning), ULiège] .citation[A. R. Barron, Neural net approximation, Yale Workshop on Adaptive and Learning Systems, 1992] --- count: false class: middle .bold[Theorem] (Barron, 1992) The mean integrated square error between the estimated network $\hat{F}$ and the target function $f$ is bounded by $$O\left(\frac{C^2\_f}{q} + \frac{qp}{N}\log N\right)$$ where $N$ is the number of training points, $q$ is the number of neurons, $p$ is the input dimension, and $C\_f$ measures the global smoothness of $f$. __.bold[tl;dr:]__ Provided enough data, it guarantees that adding more neurons will result in a better approximation. .credit[Credits: G. Louppe, [INFO8010 Deep Learning](https://github.com/glouppe/info8010-deep-learning), ULiège] .citation[A. R. Barron, Neural net approximation, Yale Workshop on Adaptive and Learning Systems, 1992] --- # Problem solved? UFA theorems **do not tell us**: - The number $h$ of hidden units small enough to have the network fit in RAM. - The optimal function parameters can be found in finite time by minimizing the Empirical Risk with SGD and the usual random initialization schemes. --- # Approximation with ReLU nets .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def rect(x, a, b, h, eps=1e-7): return h / eps * ( relu(x - a) - relu(x - (a + eps)) - relu(x - b) + relu(x - (b + eps))) x = np.linspace(-3, 3, 1000) *y = ( rect(x, -1, 0, 0.4)) plt.plot(x, y) ``` ] .right-column[ <img src="images/part14/rectangle.svg" width="100%" /> ] .reset-columns[ ] .citation[Conner Davis, [Quora: Is a single layered ReLU network still a universal approximator?](https://www.quora.com/Is-a-single-layered-ReLu-network-still-a-universal-approximator)] .credit[Credits: O. Grisel & C. Ollion, [M2DS Deep Learning](https://m2dsupsdlclass.github.io/lectures-labs/), IP Paris] --- # Approximation with ReLU nets .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def rect(x, a, b, h, eps=1e-7): return h / eps * ( relu(x - a) - relu(x - (a + eps)) - relu(x - b) + relu(x - (b + eps))) x = np.linspace(-3, 3, 1000) *y = ( rect(x, -1, 0, 0.4) * + rect(x, 0, 1, 1.3) * + rect(x, 1, 2, 0.8)) plt.plot(x, y) ``` ] .right-column[ <img src="images/part14/many_rectangles_1.svg" width="100%" /> ] .reset-columns[ ] .citation[Conner Davis, [Quora: Is a single layered ReLU network still a universal approximator?](https://www.quora.com/Is-a-single-layered-ReLu-network-still-a-universal-approximator)] .credit[Credits: O. Grisel & C. Ollion, [M2DS Deep Learning](https://m2dsupsdlclass.github.io/lectures-labs/), IP Paris] --- # Approximation with ReLU nets .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def rect(x, a, b, h, eps=1e-7): return h / eps * ( relu(x - a) - relu(x - (a + eps)) - relu(x - b) + relu(x - (b + eps))) *x = np.arange(0,5,0.05) # 10 z = np.arange(0,5,0.001) sin_approx = np.zeros_like(z) *for i in range(2, x.size-1): * sin_approx = sin_approx + rect(z,(x[i]+x[i-1])/2, * (x[i]+x[i+1])/2, np.sin(x[i]), 1e-7) plt.plot(x, y) ``` ] .right-column[ <img src="images/part14/many_rectangles_2.svg" width="100%" /> ] .reset-columns[ ] .citation[Conner Davis, [Quora: Is a single layered ReLU network still a universal approximator?](https://www.quora.com/Is-a-single-layered-ReLu-network-still-a-universal-approximator)] --- # Approximation with ReLU nets .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def rect(x, a, b, h, eps=1e-7): return h / eps * ( relu(x - a) - relu(x - (a + eps)) - relu(x - b) + relu(x - (b + eps))) *x = np.arange(0,5,0.25) # 20 z = np.arange(0,5,0.001) sin_approx = np.zeros_like(z) *for i in range(2, x.size-1): * sin_approx = sin_approx + rect(z,(x[i]+x[i-1])/2, * (x[i]+x[i+1])/2, np.sin(x[i]), 1e-7) plt.plot(x, y) ``` ] .right-column[ <img src="images/part14/many_rectangles_3.svg" width="100%" /> ] .reset-columns[ ] .citation[Conner Davis, [Quora: Is a single layered ReLU network still a universal approximator?](https://www.quora.com/Is-a-single-layered-ReLu-network-still-a-universal-approximator)] --- # Approximation with ReLU nets .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def rect(x, a, b, h, eps=1e-7): return h / eps * ( relu(x - a) - relu(x - (a + eps)) - relu(x - b) + relu(x - (b + eps))) *x = np.arange(0,5,0.1) # 50 z = np.arange(0,5,0.001) sin_approx = np.zeros_like(z) *for i in range(2, x.size-1): * sin_approx = sin_approx + rect(z,(x[i]+x[i-1])/2, * (x[i]+x[i+1])/2, np.sin(x[i]), 1e-7) plt.plot(x, y) ``` ] .right-column[ <img src="images/part14/many_rectangles_4.svg" width="100%" /> ] .reset-columns[ ] .citation[Conner Davis, [Quora: Is a single layered ReLU network still a universal approximator?](https://www.quora.com/Is-a-single-layered-ReLu-network-still-a-universal-approximator)] --- # Approximation with ReLU nets .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def rect(x, a, b, h, eps=1e-7): return h / eps * ( relu(x - a) - relu(x - (a + eps)) - relu(x - b) + relu(x - (b + eps))) *x = np.arange(0,5,0.01) # 500 z = np.arange(0,5,0.001) sin_approx = np.zeros_like(z) *for i in range(2, x.size-1): * sin_approx = sin_approx + rect(z,(x[i]+x[i-1])/2, * (x[i]+x[i+1])/2, np.sin(x[i]), 1e-7) plt.plot(x, y) ``` ] .right-column[ <img src="images/part14/many_rectangles_5.svg" width="100%" /> ] .reset-columns[ ] .citation[Conner Davis, [Quora: Is a single layered ReLU network still a universal approximator?](https://www.quora.com/Is-a-single-layered-ReLu-network-still-a-universal-approximator)] --- # Universal approximation Even if the MLP is able to represent the function, learning can fail for two different reasons: - the optimization algorithm may not be able to find the value of the parameters that correspond to the desired function - the training algorithm might chose the wrong function as result of overfitting --- # Universal approximation .grid[ .kol-4-12[ .center.width-100[] ] .kol-4-12[ .center.width-100[] ] .kol-4-12[ .center.width-100[] ] ] --- # Universal approximation Adding more neurons .left-column[ .center.width-90[] ] .right-column[ .center.width-90[] ] --- # Overparametrization and optimization ## Folklore experiment .left-column[ .center.width-60[] _Step 1:_ Generate labeled data by feeding random input vectors into depth $2$ net with hidden layer of size $n$ ] .right-column[ .center.width-60[] _Step 2:_ Difficult to train a new network using this labeled data with the same amount of hidden nodes. ] .citation[Livni et al.; 2014] --- count:false # Overparametrization and optimization ## Folklore experiment .left-column[ .center.width-60[] _Step 1:_ Generate labeled data by feeding random input vectors into depth $2$ net with hidden layer of size $n$ ] .right-column[ .center.width-60[] _Step 2:_ Difficult to train a new network using this labeled data with the same amount of hidden nodes. .red[It is much easier to train a new net with bigger hidden layer or addition layer] ] .citation[Livni et al.; 2014] --- class: middle # Benefits of depth --- # The benefits of depth .caption[GINN: Geometric Illustrations for Neural Networks (http://www.bayeswatch.com/2018/09/17/GINN/)] .center.width-40[] --- # Efficient Oscillations with Composition .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def tri(x): return relu( relu(2 * x) - relu(4 * x - 2)) x = np.linspace(-.3, 1.3, 1000) y = tri(x) plt.plot(x, y) ``` ] .right-column[ .width-100[] ] .citation[M. Telgarsky, [Benefits of depth in neural networks](https://www.youtube.com/watch?v=ssaXJqG9Dz4), COLT 2016 ] .credit[Credits: O. Grisel & C. Ollion, [M2DS Deep Learning](https://m2dsupsdlclass.github.io/lectures-labs/), IP Paris] --- # Efficient Oscillations with Composition .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def tri(x): return relu( relu(2 * x) - relu(4 * x - 2)) x = np.linspace(-.3, 1.3, 1000) *y = tri(tri(x)) plt.plot(x, y) ``` ] .right-column[ .width-100[] ] .citation[M. Telgarsky, [Benefits of depth in neural networks](https://www.youtube.com/watch?v=ssaXJqG9Dz4), COLT 2016] .credit[Credits: O. Grisel & C. Ollion, [M2DS Deep Learning](https://m2dsupsdlclass.github.io/lectures-labs/), IP Paris] --- # Efficient Oscillations with Composition .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def tri(x): return relu( relu(2 * x) - relu(4 * x - 2)) x = np.linspace(-.3, 1.3, 1000) *y = tri(tri(tri(x))) plt.plot(x, y) ``` ] .right-column[ .width-100[] ] .center[ 1 more layer → 2x more oscillations ] .citation[M. Telgarsky, [Benefits of depth in neural networks](https://www.youtube.com/watch?v=ssaXJqG9Dz4), COLT 2016 ] .credit[Credits: O. Grisel & C. Ollion, [M2DS Deep Learning](https://m2dsupsdlclass.github.io/lectures-labs/), IP Paris] --- # Efficient Oscillations with Composition .left-column[ ```python import numpy as np import matplotlib.pyplot as plt def relu(x): return np.maximum(x, 0) def tri(x): return relu( relu(2 * x) - relu(4 * x - 2)) x = np.linspace(-.3, 1.3, 1000) *y = tri(tri(tri(tri(x)))) plt.plot(x, y) ``` ] .right-column[ .width-100[] ] .center[ 1 more layer → 2x more oscillations ] .citation[M. Telgarsky, [Benefits of depth in neural networks](https://www.youtube.com/watch?v=ssaXJqG9Dz4), COLT 2016 ] .credit[Credits: O. Grisel & C. Ollion, [M2DS Deep Learning](https://m2dsupsdlclass.github.io/lectures-labs/), IP Paris] --- # Efficient Oscillations with Composition .left-column[ <br> <br> - Adding the parameters required for **one new layer** can **multiply by two the number of local oscillations** in the decision function of the model. - This is to be contrasted with the approach of adding parameters **on the same layer** (as in the rectangle example) that can only contribute an **additive number of new local oscillations**. ] .right-column[ .width-100[] ] .citation[M. Telgarsky, [Benefits of depth in neural networks](https://www.youtube.com/watch?v=ssaXJqG9Dz4), COLT 2016 ] --- class: middle .center[For a fixed parameter budget deeper is better] .center.width-80[] .citation[Montufar et al.; On the number of linear regions of deep neural networks; 2014] --- class: middle, center .bigger[In practice we observe that a good combination of layers and numbers of parameters is key for improving performance.] .hidden.bigger[However increasing capacity (i.e. number of parameters) seems to go against findings from statistical Machine Learning] --- count: false class: middle, center .bigger[In practice we observe that a good combination of layers and numbers of parameters is key for improving performance.] .bigger[However increasing capacity (i.e. number of parameters) seems to go against findings from statistical Machine Learning] --- class: middle .width-55[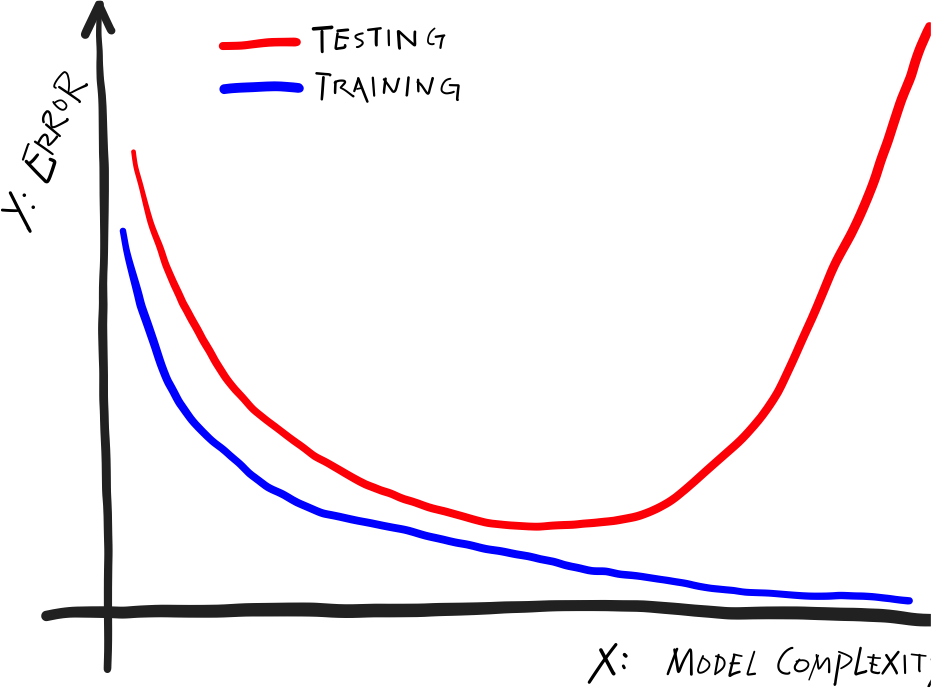] .citation[C. Zhang et al., Understanding deep learning requires rethinking generalization, ICLR 2017] --- count: false class: middle .center.width-100[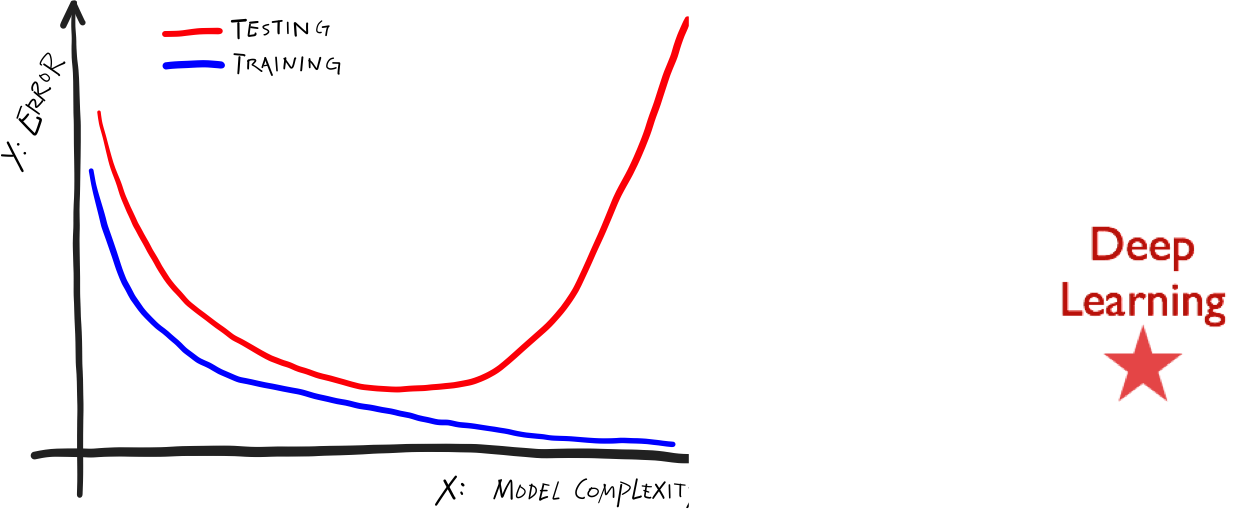] .citation[C. Zhang et al., Understanding deep learning requires rethinking generalization, ICLR 2017] --- .center.width-65[] .citation[C. Zhang et al., Understanding deep learning requires rethinking generalization, ICLR 2017] --- class: middle .center.width-90[] .citation[M. Belkin et al., Reconciling modern machine learning practice and the bias-variance trade-off, arXiv 2018] --- class: middle .center.width-60[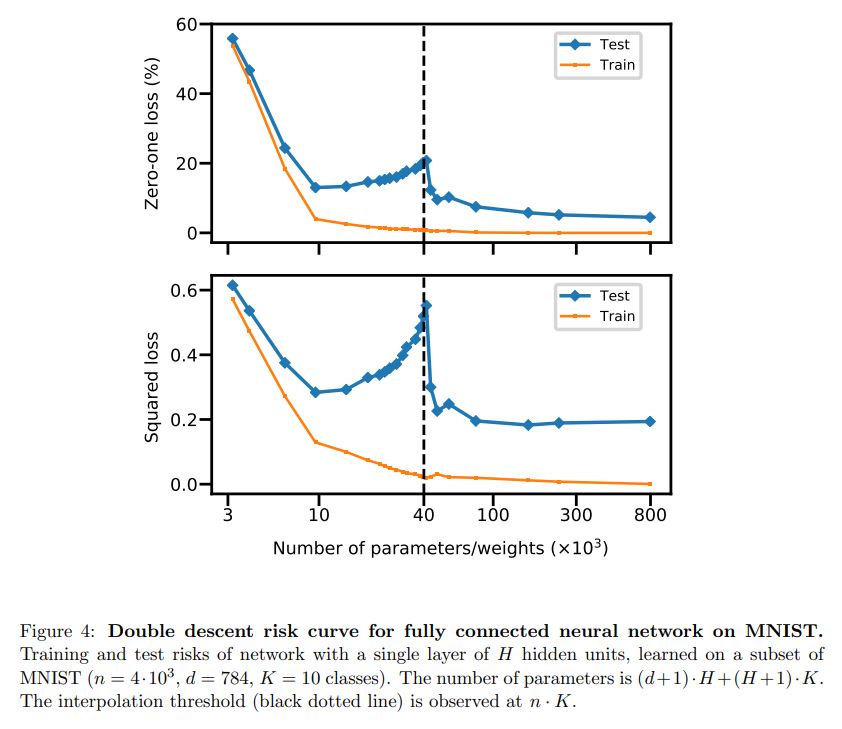] .citation[M. Belkin et al., Reconciling modern machine learning practice and the bias-variance trade-off, arXiv 2018] --- class: end-slide, center count: false The end.