layout: true .center.footer[Marc LELARGE and Andrei BURSUC | Deep Learning Do It Yourself | 14.5 ResNets] --- class: center, middle, title-slide count: false ## Going Deeper # 14.5 ResNets <br/> <br/> .bold[Andrei Bursuc ] <br/> url: https://dataflowr.github.io/website/ .citation[ With slides from A. Karpathy, F. Fleuret, G. Louppe, C. Ollion, O. Grisel, Y. Avrithis ...] --- class: middle, center ## How deep can we go now? --- # A saturation point If we continue stacking more layers on a CNN: .center.width-90[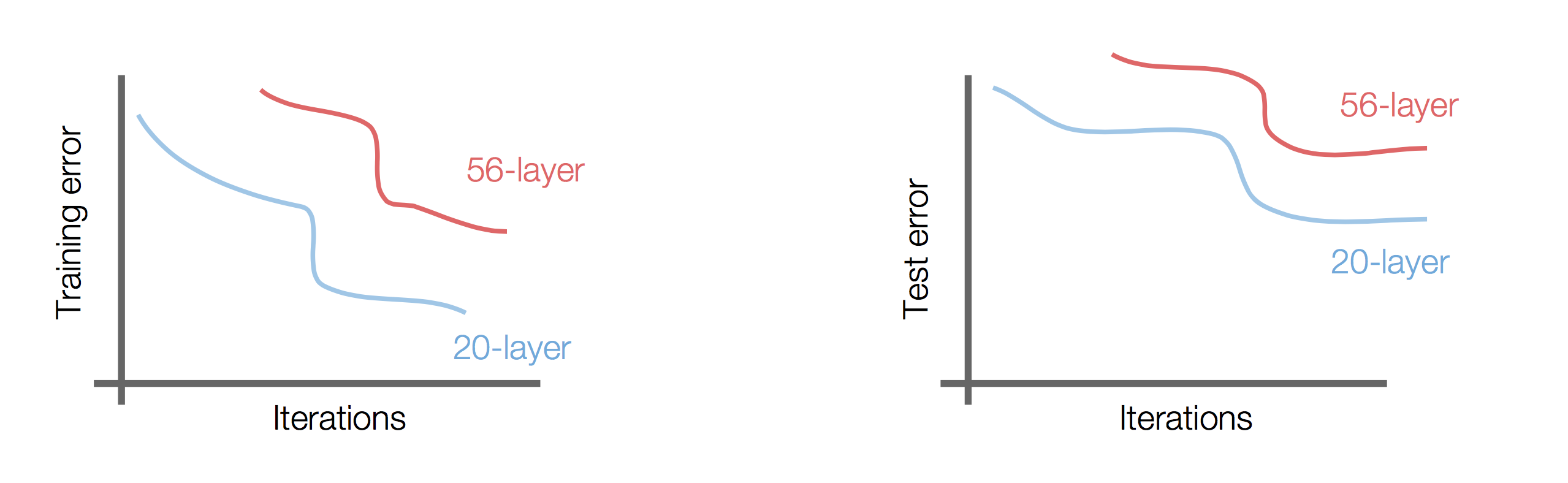] -- count: false .center[.red[Deeper models are harder to optimize]] --- .left-column[ # ResNet ] .right-column[ .center.width-50[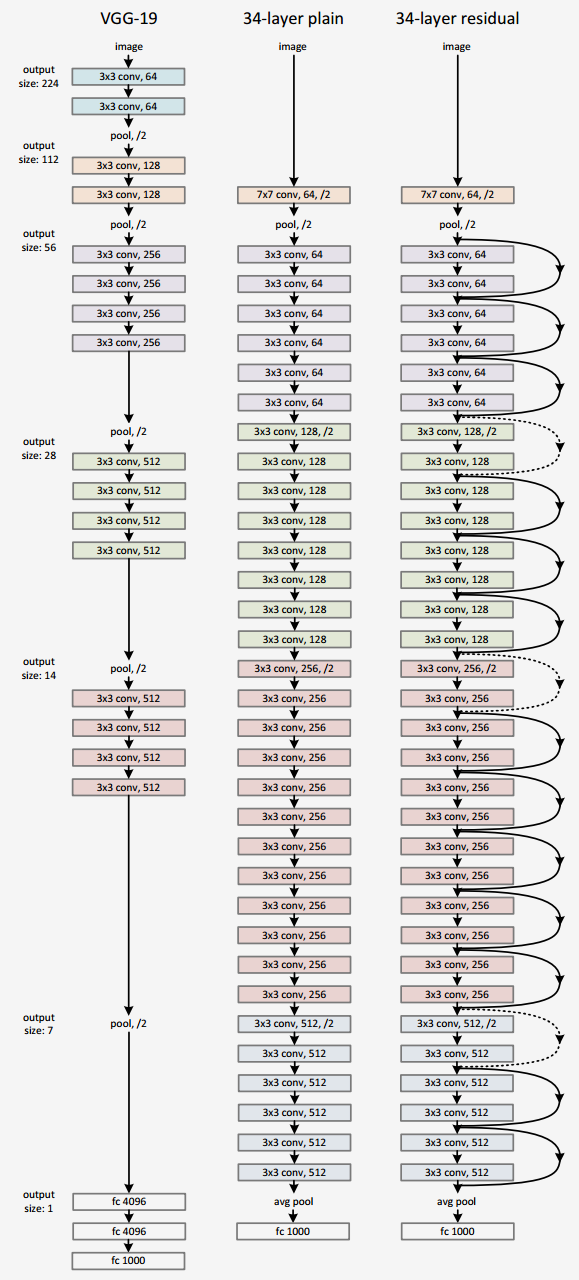] ] A block learns the residual w.r.t. identity .center.width-40[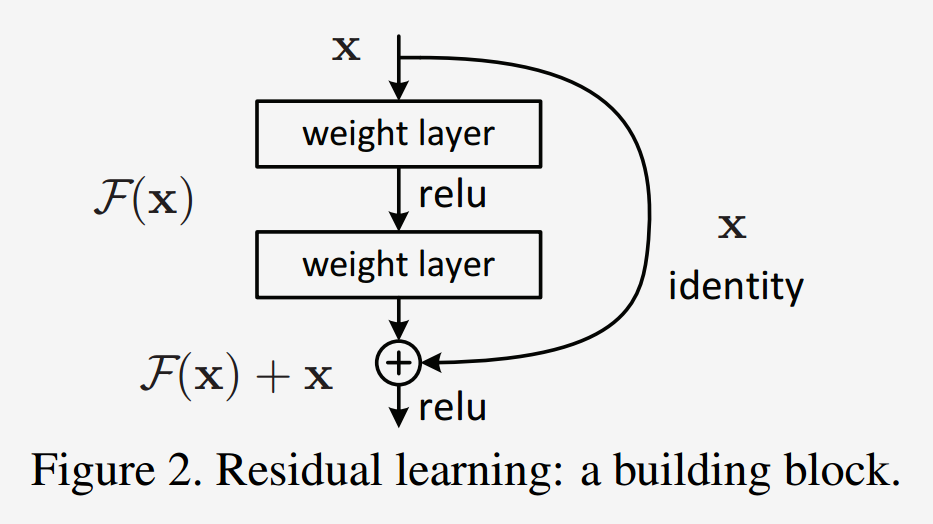] .citation[K. He et al., Deep residual learning for image recognition, CVPR 2016.] -- count: false - Good optimization properties --- .left-column[ # ResNet ] .right-column[ .center.width-50[] ] Even deeper models: 34, 50, 101, 152 layers .citation[K. He et al., Deep residual learning for image recognition, CVPR 2016.] --- .left-column[ # ResNet ] .right-column[ .center.width-50[] ] ResNet50 Compared to VGG: - Superior accuracy in all vision tasks <br/>**5.25%** top-5 error vs 7.1% .citation[K. He et al., Deep residual learning for image recognition, CVPR 2016.] -- count: false - Less parameters <br/>**25M** vs 138M -- count: false - Computational complexity <br/>**3.8B Flops** vs 15.3B Flops -- count: false - Fully Convolutional until the last layer --- # ResNet ## Performance on ImageNet .center.width-90[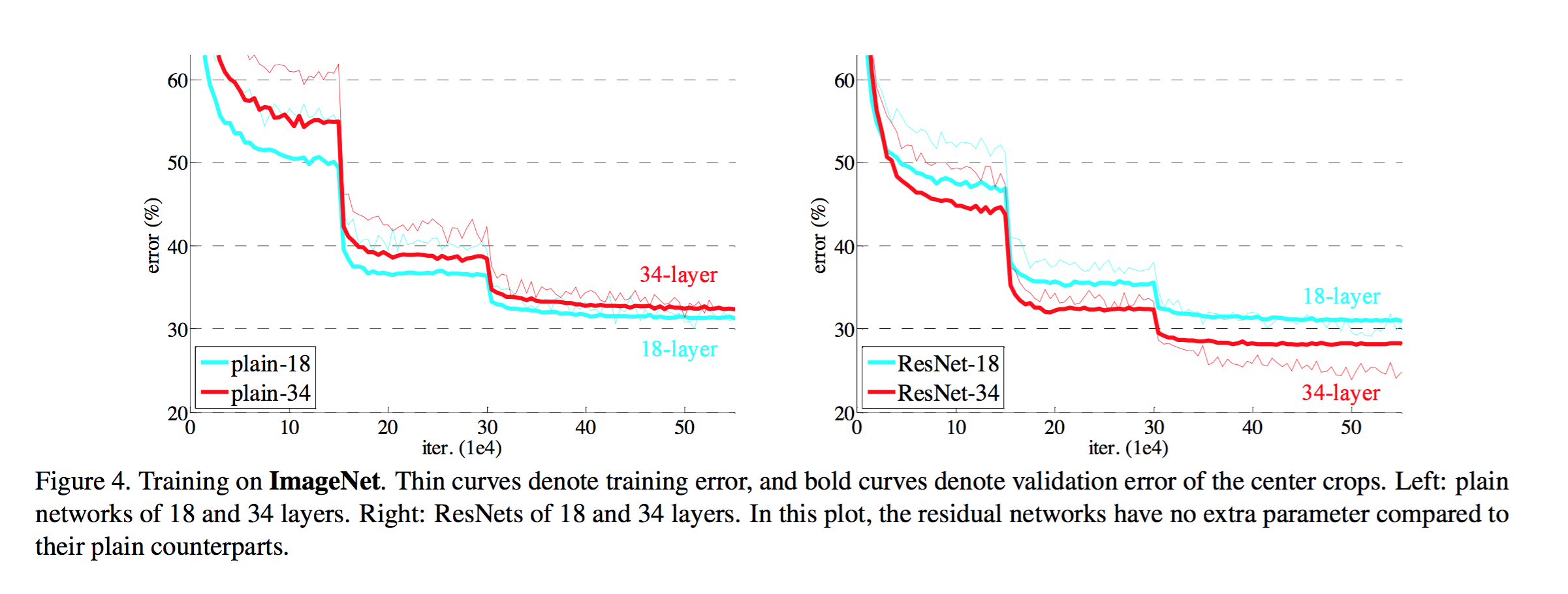] --- # ResNet ## Results .center.width-100[] --- # ResNet ## Results .center.width-60[] --- # ResNet In PyTorch: ```py def make_resnet_block(num_feature_maps , kernel_size = 3): return nn.Sequential( nn.Conv2d(num_feature_maps , num_feature_maps , kernel_size = kernel_size , padding = (kernel_size - 1) // 2), nn.BatchNorm2d(num_feature_maps), nn.ReLU(inplace = True), nn.Conv2d(num_feature_maps , num_feature_maps , kernel_size = kernel_size , padding = (kernel_size - 1) // 2), nn.BatchNorm2d(num_feature_maps), ) ``` --- # ResNet In PyTorch: ```py def __init__(self, num_residual_blocks, num_feature_maps) ... self.resnet_blocks = nn.ModuleList() for k in range(nb_residual_blocks): self.resnet_blocks.append(make_resnet_block(num_feature_maps , 3)) ... ``` ```py def forward(self,x): ... for b in self.resnet_blocks: * x = x + b(x) ... return x ``` --- For ResNet50+ layers some additional modifications need to be made to keep number of parameters and computations manageable .center.width-70[] Such a block requires $2 \times (3 \times 3 \times 256 +1) \times 256 \simeq 1.2M$ parameters .credit[Credits: F. Fleuret, [EE-559 Deep Learning](https://fleuret.org/dlc/), EPFL] -- count: false Adress this problem using __bottleneck__ block .center.width-100[] .center[$256 \times 64 + (3 \times 3 \times 64 +1) \times 64 + 64 \times 256 \simeq 70K$ parameters] --- # Stochastic Depth Networks - DropOut at layer level - Allows training up to 1K layers .center.width-70[] .citation[Huang et al., Deep Networks with Stochastic Depth, ECCV 2016] --- # DenseNet - Copying feature maps to upper layers via skip-connections - Better reuse of parameters and redundancy avoidance .center.width-30[] .center.width-70[] .citation[Huang et al., Densely Connected Convolutional Networks, CVPR 2017] --- # Squeeze-and-Excitation Networks <br/> <br/> .center.width-70[] .caption[SE block] - re-weight individual feature maps .citation[J. Hu et al., Squeeze-and-Excitation Networks, CVPR 2018] --- # Squeeze-and-Excitation Networks .center.width-50[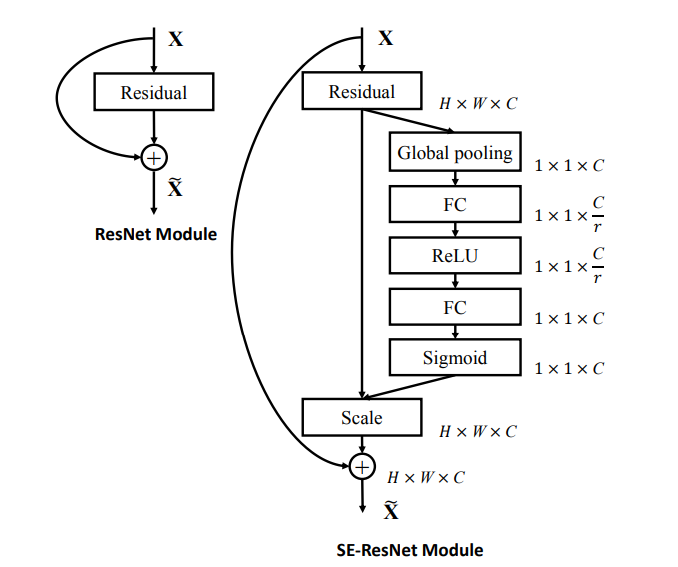] .caption[SE block] .citation[J. Hu et al., Squeeze-and-Excitation Networks, CVPR 2018] --- # Visualizing loss surfaces .center.width-70[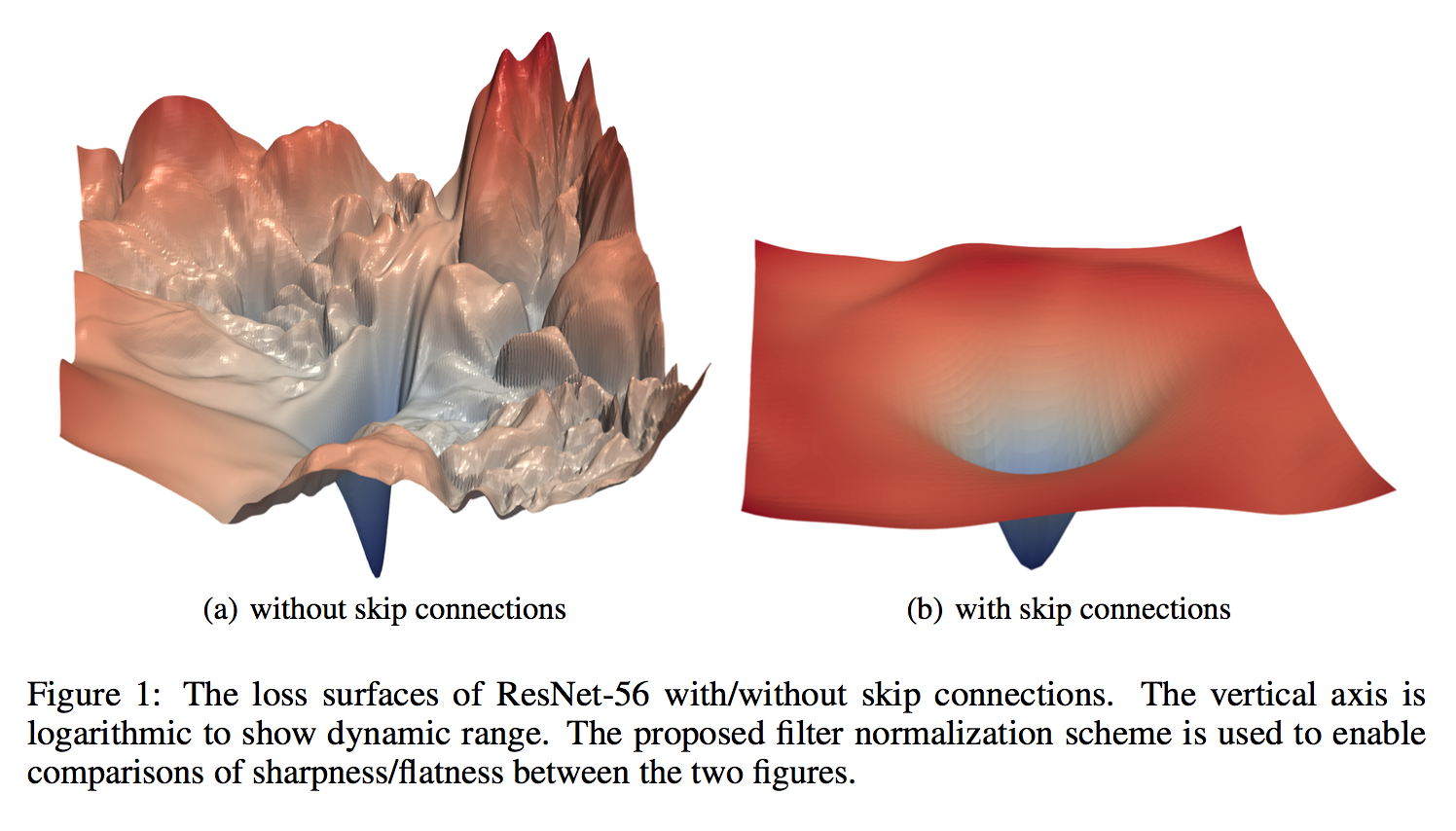] .citation[H. Li et al., Visualizing the Loss Landscape of Neural Nets, ICLR workshop 2018] --- # Visualizing loss surfaces .left-column[ .center.width-100[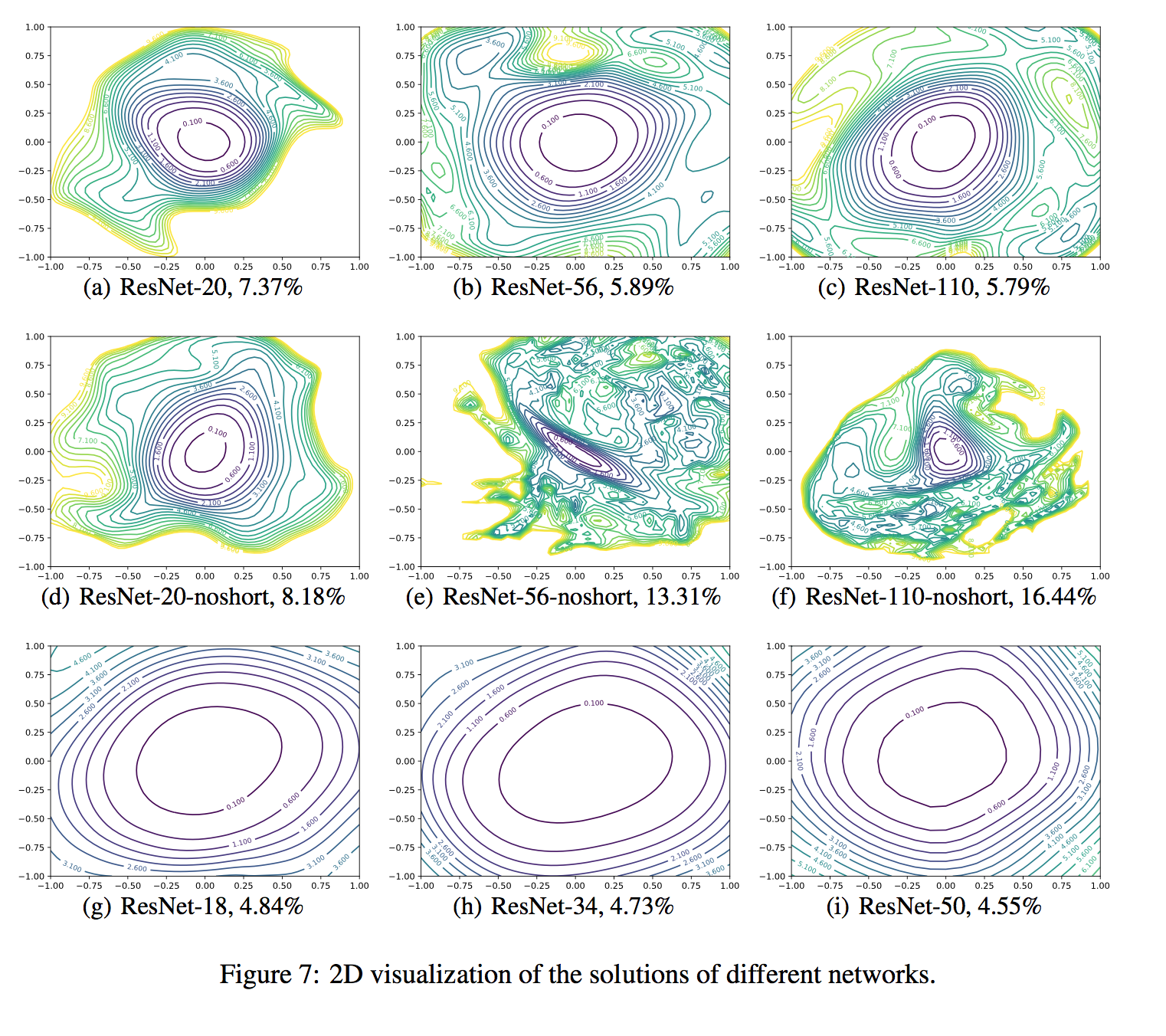] ] .right-column[ <br><br><br><br><br> - ResNet-20/56/110 : vanilla - ResNet-*-noshort: no skip connections - ResNet-18/34/50 : wide ] .citation[H. Li et al., Visualizing the Loss Landscape of Neural Nets, ICLR workshop 2018] --- # Visualizing loss surfaces .center.width-50[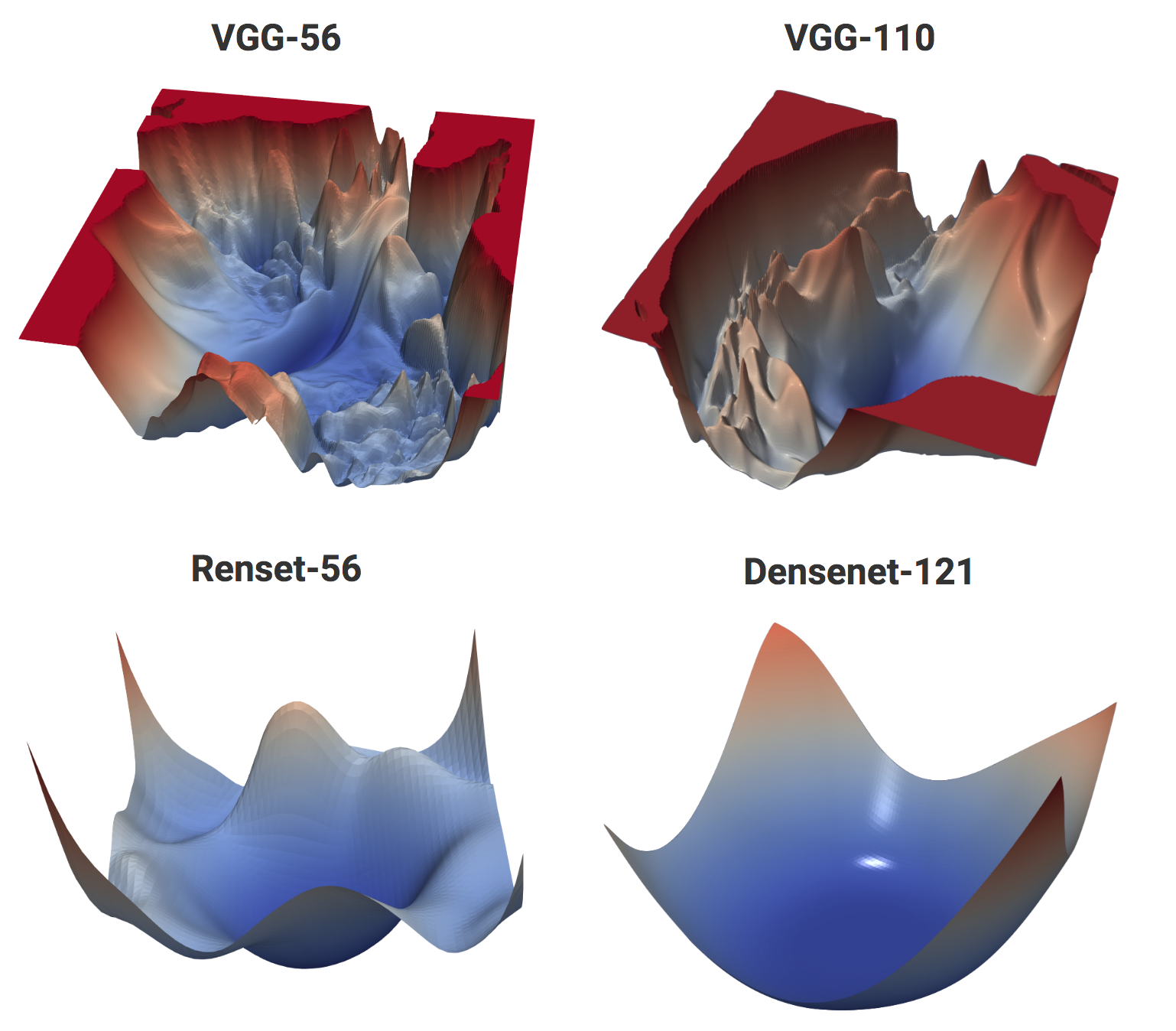] .citation[H. Li et al., Visualizing the Loss Landscape of Neural Nets, ICLR workshop 2018] --- class: end-slide, center count: false The end.